
Overview
Data is potent in the modern world. Organizations need to scale up efficiently with easy-to- maintain data pipelines. While PySpark provides Python interface to Apache Spark, utilizing Resilient Distributed Datasets (RDDs) for fault tolerance, parallel data processing across the clusters managing the infrastructure gets complex. Further, tuning it for performance gets resource intensive.
Overcoming the above-mentioned challenges is beyond just re-platforming; they demand a shift in the way we think about data engineering. Moreover, Snowflake is known for its low-maintenance infrastructure, scalable, and SQL-native architecture; it is more than just a cloud data warehouse. In this blog, we will share our real-word experiences while migrating from PySpark to Snowflake and discuss the challenges we faced, our strategic planning, the design decisions we made, and finally how the transition was implemented successfully.
The Roadblocks We Faced During Migration
Migrating ETL workloads from PySpark on Databricks to Snowpark on Snowflake, with the goal of enhancing performance, maintainability and cost-efficiency. The main agenda was to showcase that our data pipeline can handle larger volumes of data coming from file-based feed and RDBMS sources.
Let’s walkthrough the primary challenges we encountered during migration:
Developer Complexity- Debugging PySpark and handling non-portable code for slow delivery.
Platform Shift- While Snowpark is a modern alternative to Spark, there are certain features in Spark that didn’t directly translate to Snowpark, requiring workflow redesign and upskilling of team.
Job Scheduling Dependencies- Control-M was solely used for scheduling jobs across environments.
Planning for Smooth Migration
To overcome the challenges and ensure a smooth migration from PySpark on Databricks to Snowpark on Snowflake, we followed a structured and tool-driven approach.
1. Understanding the Legacy/Existing Pipelines
Understanding existing pipelines is the foremost and crucial step we adopted prior to migration.
- Identified all PySpark notebooks, ETL scripts, and job dependencies.
- Grouped pipelines by complexity and transformation type (simple joins, aggregations, window functions, etc.)
2. Strategic Approach for Migration
After analysis, we adopted a structured migration strategy that ensures optimal performance and maintainability.
- Started with low-complexity batch jobs for early wins.
- Phased out Databricks by routing eligible pipelines through Snowflake compute.
- Retained Spark only for high-frequency or unsupported real-time tasks (if any).
3. Automate Code Conversion Using Tools
Snowpark Migration Accelerator (SMA) tool is used to automate PySpark-to-snowpark code conversion.
- Snowpark code was adopted for all transformation logic to run natively within snowflake.
- Control-M was used solely for scheduling jobs across environments.
Design Strategy
With an intention to modernize our data pipelines, we restructure the code heavy design of PySpark running on Databricks to a far more efficient Snowflake-native architecture. This shift was driven by the need for simplified orchestration, scalable compute, and SQL-friendly transformations.
High Level Architecture of PySpark Running on Databricks
Using Azure Data Factory Pipelines and the ODBC connectors, data from multiple source systems are ingested into Databricks for secure and automated data movement. Within Databricks, the data is processed and transformed using scalable PySpark notebooks and subsequently loaded into the Snowflake Data Warehouse for advanced analytics and BI reporting.
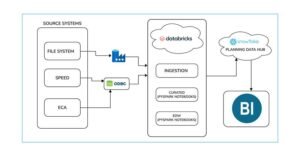
High Level Architecture of Snowpark running on Snowflake
Data is collected from multiple systems including file systems, SPEED, and ECA. Then the ingested data is loaded into the Snowflake Planning Data Hub. Once processed using Snowpark code, this clean and transformed data can be accessed by BI tools.

The Key architectural changes:
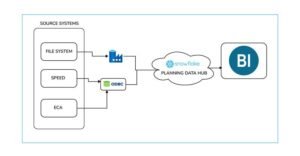
- Replacing Spark-based transformations with Snowpark code executed within Snowflake.
- Loading data directly from source systems (files and RDBMS) into Snowflake instead of staging in Databricks.
- Implementing SCD Type 2 transformations to track historical changes.
- Handling full and partial load scenarios based on business rules.
- Enabling direct reporting via BI tools connected to Snowflake.
Implementation Phases
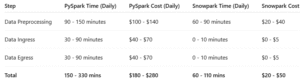
Implemented different types of data load strategies, such as full load and incremental load. Among these, implementing SCD Type 2 posed a greater challenge due to its complex transformation logic.
As mentioned earlier, the original pipelines were initially built using Apache Spark in Databricks with PySpark. For the migration from PySpark to Snowpark we leveraged the Snowflake Migration Accelerator (SMA) tool, which utilizes Snowflake’s native warehouse compute. SMA helped automate much of the code conversion, accelerating the transformation from PySpark to Snowpark.
Key considerations during conversion:
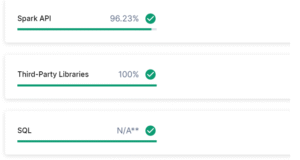
During code conversion, Pyspark libraries have been converted into native snowpark libraries. But certain transformation logic requires manual intervention to refactor and align the code with Snowpark’s execution model.

Code accuracy while migrating third party libraries is high, but there are some manual interventions required to change code.
Snowflake Benefits
- We didn’t have to manage or tune compute clusters; Snowflake handles scaling and resource allocation automatically.
- Minimal operational overhead meant we could concentrate on building and optimizing pipelines, not managing runtime environments.
- Code runs where the data lives, reducing data shuffling and improving performance, especially compared to Spark-based setups.
- Compute resources can be spun up instantly to meet workload spikes without delays or over-provisioning.
- Snowflake maintains stable performances under heavy concurrency without any need for manual intervention.
Conclusion
Migrating from PySpark to Snowpark using the SMA tool significantly reduced development effort and complexity. The SMA tool automated most of the PySpark-to-Snowpark conversion, with minimal manual adjustments required. Running Snowpark code natively inside Snowflake eliminated the need for Databricks compute and intermediate storage, simplifying infrastructure and improving performance. This wasn’t just a migration—it was an architectural upgrade that led to faster pipelines, lower costs, and more maintainable workflows.